












Gửi bình luận
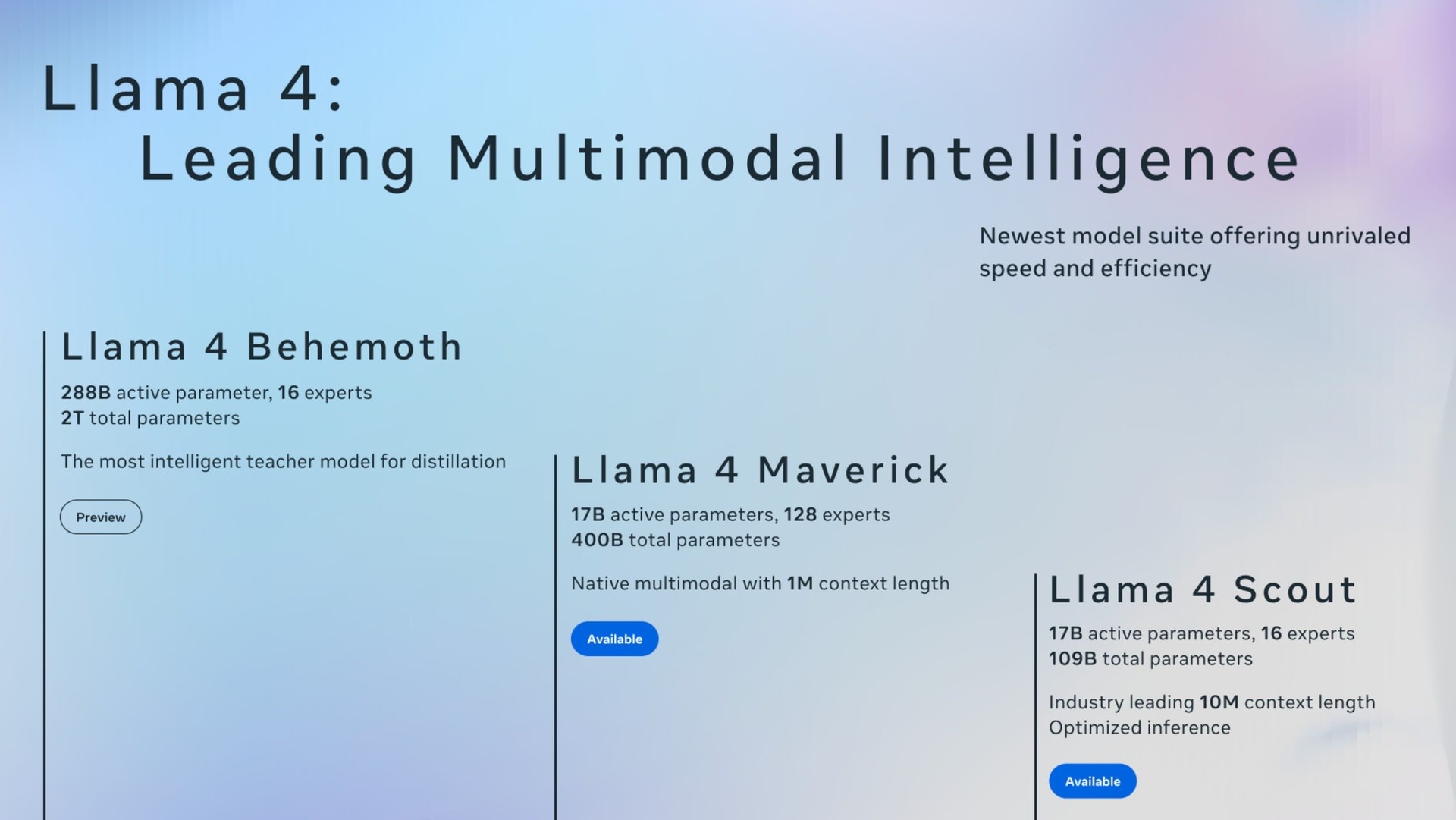
Meta Platforms hôm 5.4 đã phát hành mô hình ngôn ngữ lớn mới nhất là Llama 4, với ba phiên bản Llama 4 Scout, Llama 4 Maverick và Llama 4 Behemoth.
Công ty mẹ Facebook cho biết Llama là một hệ thống AI đa phương thức, có khả năng xử lý và tích hợp nhiều loại dữ liệu khác nhau gồm văn bản, video, hình ảnh và âm thanh, đồng thời hỗ trợ chuyển đổi nội dung giữa các định dạng này.
Theo Meta Platforms, Llama 4 Maverick và Llama 4 Scout sẽ là mô hình ngôn ngữ lớn mã nguồn mở. Công ty cho biết đang giới thiệu bản xem trước của Llama 4 Behemoth, được gọi là “một trong những mô hình ngôn ngữ lớn thông minh nhất thế giới và là mô hình mạnh mẽ nhất của chúng tôi, đóng vai trò một giáo viên cho các mô hình mới”.
Meta Platforms nói rằng Llama 4 Scout, với 17 tỉ tham số hoạt động và 16 chuyên gia, là mô hình đa phương thức tốt nhất thế giới trong phân khúc của nó, mạnh hơn tất cả thế hệ Llama trước, và có thể chạy trên một GPU (bộ xử lý đồ họa) Nvidia H100 duy nhất. Ngoài ra, Llama 4 Scout hỗ trợ cửa sổ ngữ cảnh lên đến 10 triệu token (dẫn đầu ngành) và vượt trội Gemma 3, Gemini 2.0 Flash-Lite, Mistral 3.1 trên nhiều bảng điểm chuẩn phổ biến.
Trong ngữ cảnh AI, token là đơn vị nhỏ nhất mà mô hình sử dụng để xử lý văn bản. Tùy vào cách tokenizer hoạt động, một token có thể là:
Một chữ cái, ví dụ h, e, l…
Một âm tiết hoặc phần của từ, ví dụ com, puter
Một từ đầy đủ, ví dụ hello, dog.
Thậm chí là dấu câu hoặc khoảng trắng.
Số token càng lớn thì chi phí xử lý và yêu cầu tính toán càng cao.
Llama 4 Scout có thể xử lý lên tới 10 triệu token trong một lần, nên rất mạnh trong việc xử lý văn bản dài, nhiều hình ảnh/video tích hợp.
Tokenizer là thành phần cực kỳ quan trọng trong các mô hình ngôn ngữ lớn như Llama, GPT hay Gemini. Nó là "bộ phân tách văn bản", giúp chuyển đổi văn bản thô thành các token mà mô hình có thể hiểu và xử lý.
Llama 4 Maverick, cũng với 17 tỉ tham số hoạt động nhưng có đến 128 chuyên gia, vượt qua GPT-4o và Gemini 2.0 Flash trong nhiều bài kiểm tra đánh giá, đồng thời đạt kết quả tương đương DeepSeek V3 ở các tác vụ suy luận và lập trình với chưa đến một nửa tham số hoạt động.
Theo Meta Platforms, hai mô hình này đạt được chất lượng cao nhờ vào sự tinh luyện từ Llama 4 Behemoth, mô hình lớn nhất và mạnh nhất của công ty đến nay, với 288 tỉ tham số hoạt động và 16 chuyên gia. Llama 4 Behemoth vượt trội GPT-4.5, Claude Sonnet 3.7 và Gemini 2.0 Pro ở nhiều bài kiểm tra về STEM, theo Meta Platforms. Llama 4 Behemoth vẫn đang trong quá trình huấn luyện và công ty sẽ chia sẻ thêm chi tiết trong thời gian tới.
STEM là viết tắt của Science, Technology, Engineering, and Mathematics (Khoa học, Công nghệ, Kỹ thuật và Toán học). Đây là nhóm các lĩnh vực giáo dục và nghề nghiệp tập trung vào khoa học tự nhiên, công nghệ, kỹ thuật và toán học, thường được khuyến khích vì vai trò quan trọng trong đổi mới, nghiên cứu và phát triển kinh tế. STEM đặc biệt quan trọng trong thời đại công nghệ số, khi các ngành như AI, dữ liệu lớn (Big Data) và kỹ thuật phần mềm ngày càng phát triển.
Trên trang web của mình, Meta Platforms cho biết thêm: “Những mô hình này đại diện cho tinh hoa của dòng Llama, mang đến trí tuệ đa phương thức với mức chi phí hấp dẫn, đồng thời vượt trội hơn so với nhiều mô hình khác có kích thước lớn hơn đáng kể.
Việc xây dựng thế hệ tiếp theo của các mô hình Llama đòi hỏi chúng tôi phải áp dụng nhiều phương pháp mới trong giai đoạn huấn luyện sơ bộ. Các mô hình Llama 4 mới là những mô hình đầu tiên sử dụng kiến trúc mixture of experts (MoE, tạm dịch là tổ hợp chuyên gia). Trong các mô hình MoE, mỗi token đầu vào chỉ kích hoạt một phần nhỏ trong tổng số tham số của mô hình. Kiến trúc MoE hiệu quả hơn về mặt tính toán trong cả quá trình huấn luyện và suy luận”.
Các hãng công nghệ lớn đã và đang đầu tư mạnh vào cơ sở hạ tầng trí tuệ nhân tạo (AI) sau thành công của ChatGPT do OpenAI phát triển, vốn đã thay đổi cục diện ngành công nghệ và thúc đẩy làn sóng đầu tư vào học máy.
Hôm 4.4, tờ The Information đưa tin Meta Platforms từng trì hoãn việc ra mắt mô hình ngôn ngữ lớn mới nhất. Lý do vì trong quá trình phát triển, Llama 4 không đạt được kỳ vọng của Meta Platforms về các tiêu chuẩn kỹ thuật, đặc biệt là ở các nhiệm vụ liên quan đến suy luận và toán học.
The Information cũng cho biết công ty lo ngại rằng Llama 4 kém hiệu quả hơn so với các mô hình của OpenAI trong việc thực hiện những cuộc hội thoại bằng giọng nói giống con người.
Meta Platforms dự kiến sẽ chi 60-65 tỉ USD trong năm nay để mở rộng cơ sở hạ tầng AI của mình, giữa bối cảnh các nhà đầu tư đang gây áp lực lên các hãng công nghệ lớn nhằm chứng minh lợi nhuận từ các khoản đầu tư của họ.
Meta thử nghiệm chip đào tạo AI tự thiết kế đầu tiên để giảm phụ thuộc Nvidia
Meta Platforms đang thử nghiệm chip tự thiết kế đầu tiên để đào tạo các hệ thống AI.
Đây là cột mốc quan trọng khi công ty mẹ Facebook hướng tới việc tự thiết kế nhiều chip tùy chỉnh hơn và giảm sự phụ thuộc vào nhà cung cấp bên ngoài như Nvidia, theo hai nguồn tin của Reuters.
Meta Platforms, công ty truyền thông xã hội lớn nhất thế giới, đã triển khai thử nghiệm chip này trên quy mô nhỏ và dự định mở rộng sản xuất để sử dụng rộng rãi nếu thử nghiệm thành công, các nguồn tin cho biết.
Nỗ lực phát triển chip nội bộ là một phần trong kế hoạch dài hạn của Meta Platforms nhằm giảm chi phí cơ sở hạ tầng khổng lồ, trong bối cảnh công ty đang đặt cược lớn vào các công cụ AI để thúc đẩy tăng trưởng.
Meta Platforms, chủ sở hữu của Facebook, Instagram và WhatsApp, dự đoán tổng chi phí năm 2025 sẽ vào khoảng 114 đến 119 tỉ USD, gồm cả 60 - 65 tỉ USD chi phí vốn chủ yếu do chi tiêu cho cơ sở hạ tầng AI.
Một nguồn tin cho biết chip đào tạo AI mới của Meta Platforms là bộ tăng tốc chuyên dụng, tức được thiết kế để xử lý các tác vụ cụ thể về AI. Điều này có thể giúp nó tiết kiệm năng lượng hơn so với các GPU tích hợp thường được sử dụng cho các tác vụ AI.
Meta Platforms đang hợp tác với TSMC để sản xuất chip này, nguồn tin này cho biết. TSMC là hãng sản xuất chip theo hợp đồng số 1 thế giới, có trụ sở ở Đài Loan.
Việc triển khai thử nghiệm bắt đầu sau khi Meta Platforms hoàn thành tape-out đầu tiên của chip. Tape-out là dấu mốc quan trọng trong quá trình phát triển chip, liên quan đến việc gửi thiết kế ban đầu đến một nhà máy sản xuất chip.
Một quy trình tape-out thông thường tốn hàng chục triệu USD và mất khoảng ba đến sáu tháng để hoàn thành, nhưng không có gì đảm bảo rằng thử nghiệm sẽ thành công. Nếu thất bại, Meta Platforms sẽ phải chẩn đoán vấn đề và lặp lại bước tape-out.
Chip này là sản phẩm mới nhất trong loạt chip Meta Training and Inference Accelerator (MTIA) của công ty. Chương trình này đã có khởi đầu chông chênh trong nhiều năm và từng hủy bỏ một chip ở giai đoạn phát triển tương tự.
Song năm ngoái, Meta Platforms bắt đầu sử dụng chip MTIA để thực hiện suy luận cho các hệ thống đề xuất quyết định nội dung hiển thị trên bảng tin Facebook và Instagram.
Suy luận là quá trình sử dụng mô hình AI đã được đào tạo để đưa ra dự đoán hoặc quyết định dựa trên dữ liệu mới. Ví dụ, khi bạn tương tác với một chatbot AI, hệ thống sẽ sử dụng quá trình suy luận để đưa ra phản hồi phù hợp.
Các lãnh đạo Meta Platforms muốn bắt đầu sử dụng chip tự thiết kế vào năm 2026 để đào tạo AI. Đây là quá trình tính toán chuyên sâu liên quan đến việc cung cấp lượng lớn dữ liệu cho hệ thống AI để "dạy" nó cách thực hiện các tác vụ.
Giống như chip suy luận, mục tiêu của chip đào tạo là bắt đầu với các hệ thống đề xuất và sau đó sử dụng nó cho sản phẩm AI tạo sinh như chatbot Meta AI, theo các lãnh đạo công ty.
"Chúng tôi đang nghiên cứu cách thực hiện đào tạo cho hệ thống đề xuất, sau đó là cách đào tạo và suy luận cho AI tạo sinh", Chris Cox, Giám đốc Sản phẩm của Meta Platforms, nói tại hội nghị công nghệ, truyền thông và viễn thông Morgan Stanley tuần trước. Morgan Stanley là một trong những ngân hàng đầu tư và công ty dịch vụ tài chính đa quốc gia lớn nhất thế giới.
Chris Cox mô tả nỗ lực phát triển chip của Meta Platforms đến nay là "kiểu như đi bộ, bò, rồi chạy", nhưng cho biết các lãnh đạo coi chip suy luận thế hệ đầu tiên cho hệ thống đề xuất là một "thành công lớn".
Trước đây, Meta Platforms đã hủy bỏ một chip suy luận tùy chỉnh nội bộ sau khi nó thất bại trong đợt triển khai thử nghiệm quy mô nhỏ tương tự đang thực hiện cho chip đào tạo. Kết quả là công ty phải đảo ngược hướng đi và đặt mua nhiều tỉ USD GPU Nvidia vào năm 2022.
Kể từ đó, công ty truyền thông xã hội này vẫn là một trong những khách hàng lớn nhất của Nvidia, tích lũy kho GPU để đào tạo các mô hình AI, gồm cả các hệ thống đề xuất và quảng cáo cũng như hàng loạt mô hình nền tảng Llama. Các đơn vị này cũng thực hiện suy luận cho hơn 3 tỉ người sử dụng ứng dụng của Meta Platforms mỗi ngày.
Giá trị của những GPU này đã bị đặt dấu hỏi trong năm nay khi các nhà nghiên cứu AI ngày càng bày tỏ nghi ngờ về việc liệu có thể đạt được bao nhiêu tiến bộ nữa bằng cách tiếp tục mở rộng quy mô các mô hình ngôn ngữ lớn thông qua thêm ngày càng nhiều dữ liệu và sức mạnh tính toán.
Sự nghi ngờ này được củng cố do công ty khởi nghiệp DeepSeek (Trung Quốc) ra mắt V3 và R1, hai mô hình AI nguồn mở có hiệu suất cao với chi phí đào tạo thấp. V3 và R1 được tối ưu hóa hiệu quả tính toán bằng cách dựa nhiều hơn vào suy luận so với hầu hết mô hình hiện có.
Trong đợt bán tháo cổ phiếu AI toàn cầu do DeepSeek gây ra cuối tháng 1, vốn hóa thị trường của Nvidia mất gần 600 tỉ USD hôm 27.1.










